一當以UTF-16或UTF-32來將UCS/統一碼字元所組成的字串編碼時,這個字元被用來標示其位元組序。
在某些平台,尤其是Win32的系統,txt檔案都喜歡在檔案的最開頭以 U+FEFF 這個字元來辦識該檔案是使用 BE ( Big Endian) 或 LE ( Little Endian) 的方式來編碼,不過它到底是怎麼去判斷是哪種編碼型態?打開記事本(NotePad),從存檔的對話視窗當中你可以看到他有幾種不同的存檔編碼格式可以選擇:
- ANSI
- Unicode
- Unicode big endian
- Utf-8
| 編碼 | 表示(十六進位) | 表示(十進位) |
|---|---|---|
| UTF-8 | EF BB BF | 239 187 191 |
| UTF-16(大端序) | FE FF | 254 255 |
| UTF-16(小端序) | FF FE | 255 254 |
| UTF-32(大端序) | 00 00 FE FF | 0 0 254 255 |
| UTF-32(小端序) | FF FE 00 00 | 255 254 0 0 |
| UTF-7 | 2B 2F 76和以下的一個位元組:[ 38 | 39 | 2B | 2F ] | 43 47 118和以下的一個位元組:[ 56 | 57 | 43 | 47 ] |
| en:UTF-1 | F7 64 4C | 247 100 76 |
| en:UTF-EBCDIC | DD 73 66 73 | 221 115 102 115 |
| en:Standard Compression Scheme for Unicode | 0E FE FF | 14 254 255 |
| en:BOCU-1 | FB EE 28 及可能跟隨著FF | 251 238 40 及可能跟隨著255 |
| GB-18030 | 84 31 95 33 | 132 49 149 51 |
資料來源
http://zh.wikipedia.org/wiki/%E4%BD%8D%E5%85%83%E7%B5%84%E9%A0%86%E5%BA%8F%E8%A8%98%E8%99%9F
https://atedev.wordpress.com/2007/09/19/bom-bom-bom/
為什麼我會知道BOM這位隱士呢?因為我要用C#傳輸一個檔案的內容給Java接收,並且算出MD5確定檔案內容是相符的,例如我用C#為Client產生了一個XML檔案(以C# 內建的 XmlDocument )產生如下內容。

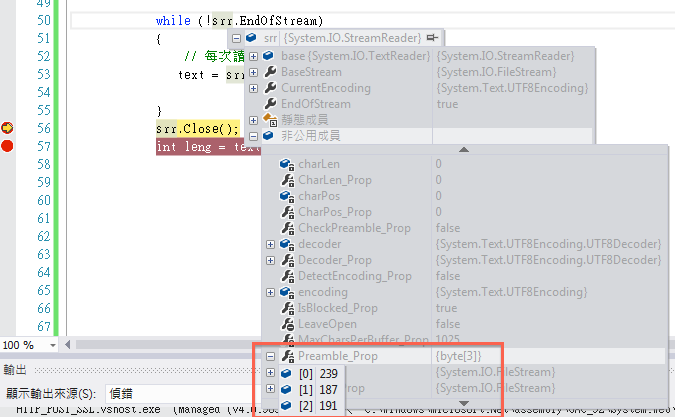
當我用C#讀檔後,Stream的長度是80。

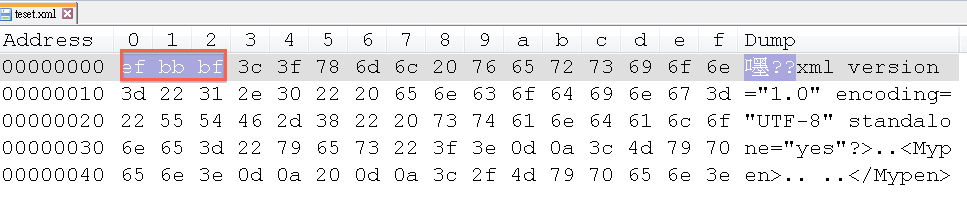
用NotePad ++ 打開來看(要裝外掛才能看十六進制)

每一行16個,共五行,沒錯是80個byte。接下來我把它讀到底看看長度。

靠北邊走了,長度只有77,還有3兄弟勒,重點來了,這個檔案編碼格式是UTF-8,所以它的前3碼是 EF BB BF ,(請先忽略大小寫,那個是NotePad++ HEX都以小寫作顯示)
那這三位元跑去那了,C#沒有把它當作內容,而是存在 Preamble Prop 裡。
就是這三個位元使我傳到另外一邊寫檔後無法得到相同的MD5 值,只有2條路可以走,要嘛不採計這3個位元(程式寫好用檔案去算MD5了),要嘛在java寫檔時多補進這3個位元 ,看起來這條路比較可以偷懶一下。code 這樣寫BufferedWriter out = new BufferedWriter(new FileWriter(檔案));
以上程式參考自http://stackoverflow.com/questions/4389005/how-to-add-a-utf-8-bom-in-java基本上JAVA預設以UTF-8寫檔是沒這東西啦, 讀檔時遇到BOM也要稍微注意一下。本篇是遇到問題後排除所寫的心得,若有錯誤,請不吝指正,謝謝。
out.write('\ufeff');out.write(檔案的內容);以上程式參考自http://stackoverflow.com/questions/4389005/how-to-add-a-utf-8-bom-in-java基本上JAVA預設以UTF-8寫檔是沒這東西啦, 讀檔時遇到BOM也要稍微注意一下。本篇是遇到問題後排除所寫的心得,若有錯誤,請不吝指正,謝謝。
沒有留言:
張貼留言